Module 1: Incident Handling Process

Incident Response (IR) requires a structured, intelligence-driven approach. It is important for every organization because incidents are not only technical problems; they are business, legal, operational, and security problems at the same time.
The core objective of incident handling is to manage and respond to security events in a way that minimizes data theft, service disruption, attacker persistence, and long-term business impact.
The NIST Incident Handling Lifecycle gives a practical blueprint:
- Preparation
- Detection and Analysis
- Containment, Eradication, and Recovery
- Post-Incident Activity
Key Point
Why do we not just rebuild impacted systems immediately and move on?
Because if we do not understand exactly how the incident happened, including the tools, attack path, root cause, and affected systems, the attacker can simply repeat the same steps and regain access.
Incident response is not just about cleaning infected systems. It is about understanding the attack deeply enough to remove the attacker, close the weakness, and prevent the same attack from working again.

Phase 1: Preparation
Key Takeaway: Build your jump bag, define your process, and keep incident communications out-of-band.
Preparation is not just about having a document called an IR plan. It means making sure the people, tools, procedures, communication channels, and defensive controls are ready before an incident happens.
A practical IR team should have a “jump bag” ready. This includes the hardware, software, credentials, forensic tools, collection scripts, documentation templates, and access needed during an active investigation. If the team has to buy tools, request access, or figure out procedures during the incident, valuable time is lost.
Preparation also requires secure, out-of-band communication. When an incident is first detected, defenders do not know how far the attacker has reached. Internal email, chat, or documentation platforms may already be monitored. For that reason, incident communication and investigation notes should be kept outside the potentially compromised environment.
A mature IR program also needs three layers of governance:
- IR Policy: Defines authority, expectations, and what the organization considers an incident.
- IR Plan: Defines roles, communication paths, escalation, severity levels, and responsibilities.
- IR Procedures / Playbooks: Step-by-step actions for common incident types such as phishing, ransomware, malware, credential compromise, or data leakage.
Good preparation also includes proactive hardening. This may sound basic in labs, but many organizations still fail at the basics: deploying EDR, enforcing MFA, disabling weak protocols like LLMNR, implementing LAPS, reducing unnecessary admin privileges, improving email security with SPF/DKIM/DMARC, and making sure logs are centralized and usable.

Security controls should not only exist on paper; they should actually reduce risk when tested. A control that looks strong but is easy to bypass gives a false sense of security, which is exactly why preparation and validation matter.
Phase 2: Detection and Analysis
Key Takeaway: Avoid tunnel vision by using a cyclic investigation loop.
When an alert fires, the responder should not immediately jump to conclusions. Focusing only on one malicious file, one IP address, or one infected host can create tunnel vision and lead to an incomplete investigation.
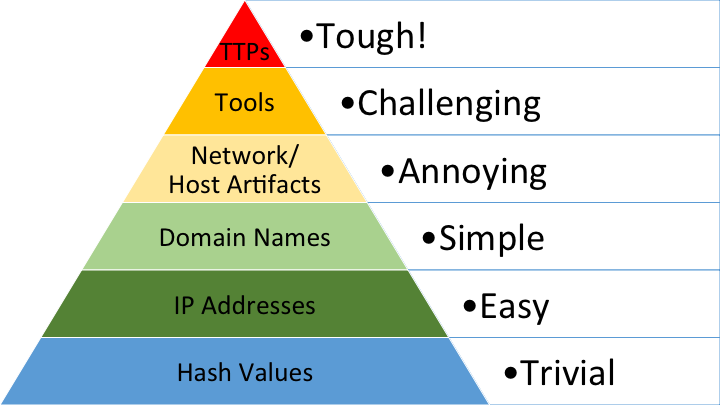
This is where the Pyramid of Pain mindset becomes important. The goal is not only to block simple indicators like hashes, domains, or IP addresses. The goal is to understand the adversary’s behavior, tools, techniques, and procedures well enough to make their operation harder to repeat.
At the same time, responders must be careful not to alert the attacker too early. Depending on how far the attacker has gone, defensive actions should be timed carefully. If the team starts blocking or isolating systems too soon, the attacker may realize they are being hunted, change tactics, destroy evidence, or move deeper into the environment.
A better approach is cyclic:
- Identify an Indicator of Compromise (IOC).
- Use that IOC to find new leads and impacted systems.
- Collect data from those systems.
- Generate more IOCs and repeat the loop.
As evidence is collected, the team should build a timeline of attacker activity. A timeline helps answer what happened first, how the attacker moved, what systems were touched, and what actions were performed.
This also helps map attacker behavior to the MITRE ATT&CK framework. By doing this, defenders move up the Pyramid of Pain: instead of only blocking easy-to-change indicators like IP addresses and hashes, they identify behaviors and TTPs that are harder for the attacker to change.

Detection can come from many places: a SOC analyst, an employee reporting suspicious activity, an automated alert, threat intelligence, or a security tool.
Detection should also happen across multiple layers:
- Network detection: Suricata, Zeek, RITA, firewall logs, proxy logs, DNS logs
- Endpoint detection: EDR, Sysmon, Windows Event Logs, process creation logs
- Forensic collection: Velociraptor, disk artifacts, memory captures
- Centralized analysis: SIEM, dashboards, alert correlation, case management
Strong analysis does not rely on one alert source. It correlates activity across network, endpoint, application, identity, and system logs.
Phase 3: Containment, Eradication, and Recovery
Key Takeaway: Do not contain piecemeal. Understand the scope, preserve evidence, remove the root cause, then recover carefully.
Containment is one of the most strategic phases of IR. If the team finds ten compromised systems but only isolates five, the attacker may realize they have been discovered and change tools, destroy evidence, or move deeper into the network.

Short-term containment should be coordinated and executed across all known affected systems. Examples include isolating hosts, placing systems in a restricted VLAN, blocking malicious domains, disabling compromised accounts, or sinkholing attacker infrastructure.
Evidence collection is critical before aggressive cleanup. Disk images, memory captures, logs, malware samples, attacker tools, and forensic artifacts should be preserved before systems are wiped or rebuilt.
A major lesson is that root cause analysis must go deeper than the first visible mistake. Saying “the user clicked a phishing link” is not enough. The deeper root cause might be missing MFA, weak email filtering, overprivileged users, poor logging, exposed services, unpatched software, or missing endpoint controls.
After root cause is identified, the team must ask:
Where else can this same attack path work?
Fixing one infected machine is not enough if the same weakness exists across the environment. Responders must identify other vulnerable systems before the attacker does.
Eradication includes removing malware, deleting attacker tools, disabling persistence, rotating credentials, patching vulnerabilities, closing exposed paths, and improving controls.
Recovery should be treated as three separate steps:
- Restore: Bring systems and services back safely.
- Validate: Confirm business functionality and security posture.
- Monitor: Watch closely for reinfection, suspicious logons, registry changes, persistence, abnormal processes, or unusual network traffic.
A restored system should be treated as high-risk until monitoring proves it is stable.
Phase 4: Post-Incident Activity
Key Takeaway: The incident is not truly over until lessons learned become action items.
It is easy to declare victory once systems are back online, but the incident is not fully handled until the team documents what happened, what actions were taken, what worked, what failed, and what must improve.
The final report should include the incident timeline, affected systems, root cause, containment actions, eradication steps, recovery actions, business impact, evidence collected, and recommendations. If legal action or insurance claims are involved, the report may also help show the cost and impact of the breach.
A lessons-learned meeting should be held after the incident. The goal is not to blame people. The goal is to improve the organization.
Important questions include:
- Did we detect the incident fast enough?
- Were communications clear?
- Did we have the right tools?
- Were logs available and useful?
- Did the business provide information quickly?
- Were roles and responsibilities clear?
- What controls would have prevented or reduced the impact?
Most importantly, every gap should become a tracked action item with an owner, deadline, and follow-up lead.
Examples:
- Improve logging coverage
- Tune SIEM detections
- Update playbooks
- Enforce MFA
- Harden vulnerable systems
- Validate backups
- Train users and analysts
- Add missing forensic tools
- Improve incident communication channels
The best IR teams do not just recover from incidents. They evolve because of them.
Where AI Can Help

Honestly, AI can help a lot in Incident Response, but it should not replace human judgment. One thing AI cannot fully replace is analyst experience: the ability to pivot from one lead to another, recognize patterns across different incidents, apply analytical thinking, and understand the environment behind the logs.
AI can definitely speed up the work. It can help responders move faster, organize information, and reduce the time spent on repetitive analysis. But the rule should always be trust, but verify. Foundational knowledge, hands-on skill, and security judgment still matter because the responder is responsible for the final decision.
AI can support responders by summarizing logs, explaining suspicious commands, helping build timelines, mapping activity to MITRE ATT&CK, drafting reports, generating detection logic, and speeding up research during an investigation.
But AI also has limits. It can hallucinate, miss context, or explain something incorrectly with confidence, and that risk is very real. In Incident Response, this is dangerous because it can send an investigation down the wrong path. Every AI-assisted conclusion must be validated with evidence from logs, forensic artifacts, endpoint data, network traffic, or trusted documentation.
My honest takeaway is this: AI is useful as an assistant for speed, structure, and explanation, but the responder is still responsible for verification, decisions, containment strategy, and final conclusions.
Final Takeaway
Incident Response is not a linear checklist. It is a disciplined cycle of preparation, investigation, containment, remediation, recovery, and improvement. The exact process can vary depending on the organization, incident depth, timeline, impact, available evidence, and team coordination.
The real goal is not only to remove the attacker. The real goal is to understand the attack well enough that the same path cannot be used again.
Helpful Resources
- NIST SP 800-61 Rev. 3: Incident Response Recommendations and Considerations
- NIST SP 800-61 Rev. 2: Computer Security Incident Handling Guide
- SANS Incident Handler’s Handbook
- CISA Cybersecurity Incident and Vulnerability Response Playbooks
- MITRE ATT&CK Framework
- Pyramid of Pain by David Bianco
- TheHive Project - Incident Response Platform
- Velociraptor DFIR
- Suricata IDS/IPS
- Microsoft Sysmon